
This is a bash script I wrote for quickly grabbing the S.M.A.R.T status on all drives attached to a system along with their current temperatures. It uses ‘smartctl’ from smartmontools (www.smartmontools.org) to grab the SMART information from drives and presents snippets of that information in a nicely formatted table, including:
- path of the drive
- temperature reading
- model number
- serial number
- overall SMART status
Here’s what it looks like, on one of my servers
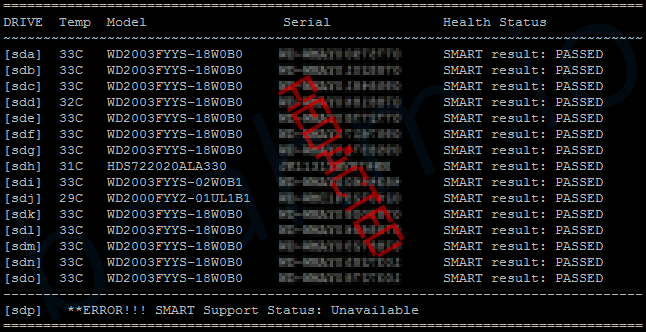
Feel free to grab this script’s source code below; using or altering as you’d like
#! /bin/bash
##
# prints formatted SMART results for all drives
# tested and working on: Ubuntu 18.04.1 LTS (Bionic Beaver)
##
echo "================================================================================"
echo "DRIVE::Temp::Model::Serial::Health Status" | awk -F:: '{printf "%-7s%-6s%-22s%-20s%s\n", $1, $2, $3, $4, $5}'
echo "~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"
for i in $(lsblk | grep -E "disk" | awk '{print $1}')
do
DevSupport=`smartctl -a /dev/$i | awk '/SMART support is:/{print $0}' | awk '{print $4}' | tail -1`
if [ "$DevSupport" == "Enabled" ]
then
DevTemp=`smartctl -a /dev/$i | awk '/Temperature/{print $0}' | awk '{print $10 "C"}'`
DevSerNum=`smartctl -a /dev/$i | awk '/Serial Number:/{print $0}' | awk '{print $3}'`
DevName=`smartctl -a /dev/$i | awk '/Device Model:/{print $0}' | awk '{print $4}'`
DevStatus=`smartctl -a /dev/$i | awk '/SMART overall-health/{print $0}' | awk '{print $1" "$5" "$6}'`
echo [$i]::$DevTemp::$DevName::$DevSerNum::$DevStatus | awk -F:: '{printf "%-7s%-6s%-22s%-20s%s\n", $1, $2, $3, $4, $5}'
fi
done
##
# now find drives that don't have SMART enabled and warn user about these drives
##
echo "--------------------------------------------------------------------------------"
for i in $(lsblk | grep -E "disk" | awk '{print $1}')
do
DevSupport=`smartctl -a /dev/$i | awk '/SMART support is:/{print $0}' | awk '{print $4}' | tail -1`
if [ "$DevSupport" != "Enabled" ]
then
echo [$i]::$DevSupport | awk -F:: '{printf "%-6s **ERROR!!! SMART Support Status: %s\n", $1, $2}'
fi
done
echo "================================================================================"
I’m still new to the Linux/Unix universe and scripting on it. Please let me know if you run into any problems or if you have suggestions on how I can improve my script or feel free to give my any feedback you may have!
Script was built using the following:
— Ubuntu: 18.04.1 LTS – Bionic Beaver
— Smartmontools: 6.6 – SVN rev 4324
— GNU bash: 4.4.19(1)-release (x86_64-pc-linux-gnu)
**Drives must have SMART support, along with enabling SMART in the system’s BIOS
For now this script is pretty basic barely skims the surface on managing drives properly, therefore you shouldn’t rely on this as the only form of health checks for your drives.
I plan to work more on drive monitoring scripts and hopefully will be able to offer more in the future. I’d love to see any improvements and variants you create on this scripts, or scripts you use for drive monitoring. Feel free to share them in the comments!
I’ve enjoyed scripting on Linux and look forward to learning more, thanks for reading




